Code Coverage bezeichnet den messbaren Anteil eines Programmcodes, der durch Tests tatsächlich ausgeführt wird. Der Begriff stammt aus der Software-Qualitätssicherung und ist vor allem in der Verifikation und Validierung von Software relevant. In der Embedded-Entwicklung hat Code Coverage jedoch eine deutlich größere praktische Bedeutung als in vielen klassischen IT-Anwendungen, weil hier Software direkt mit physischer Hardware, sicherheitsrelevanten Funktionen und oft schwer zugänglichen Fehlerszenarien verbunden ist.
Inhalt
Wozu braucht man Code Coverage?
Code Coverage beantwortet im Kern die Frage: Welche Teile des Codes wurden durch meine Tests wirklich erreicht? Dabei geht es nicht darum, ob der Test „bestanden“ wurde, sondern ob bestimmte Anweisungen, Verzweigungen, Bedingungen oder Pfade überhaupt ausgeführt wurden.
Typische Arten von Code Coverage sind:
- Statement Coverage
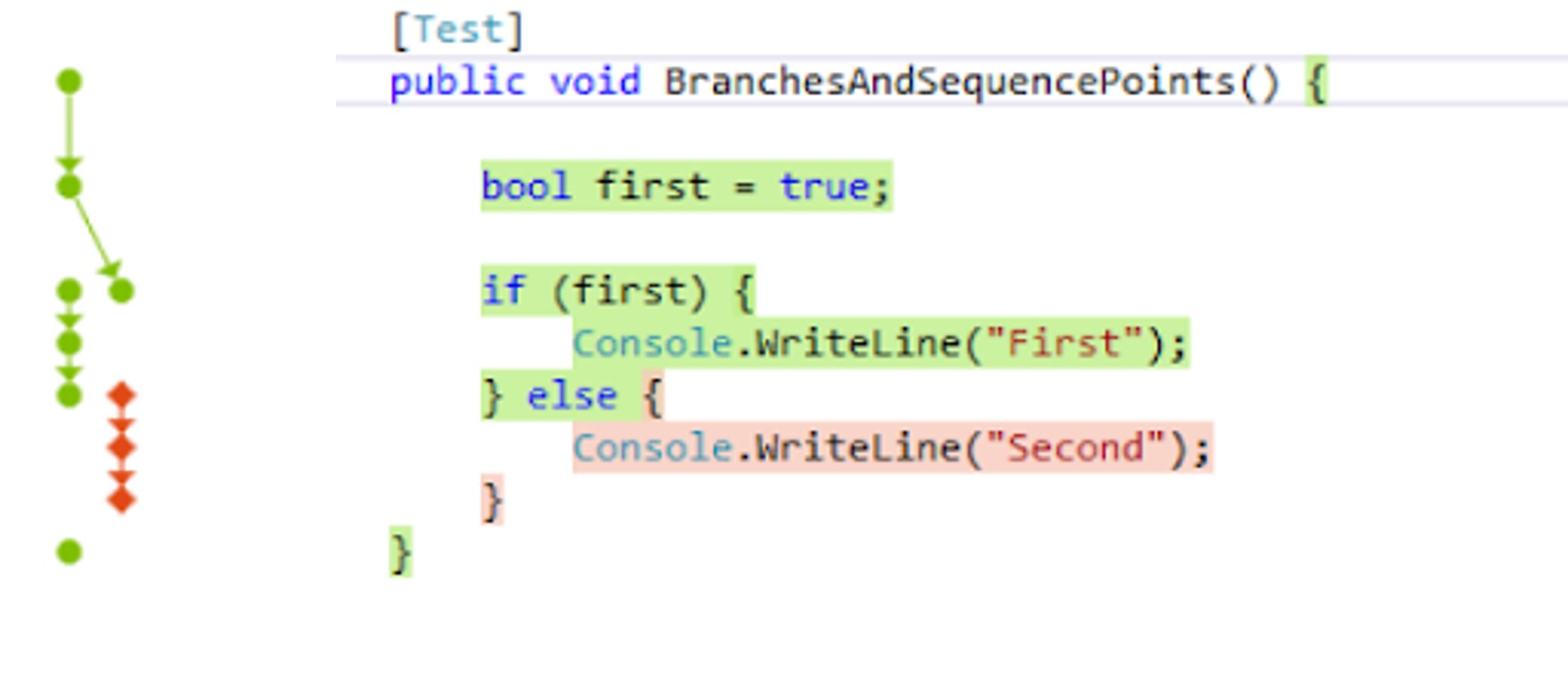
Misst, welche einzelnen Anweisungen mindestens einmal ausgeführt wurden. - Branch Coverage
Misst, ob beide Richtungen einer Verzweigung getestet wurden, also beispielsweiseifundelse. - Condition Coverage
Misst, ob einzelne logische Teilbedingungen innerhalb komplexer Ausdrücke jeweils wahr und falsch waren. - Path Coverage
Betrachtet vollständige Ausführungspfade durch den Code. Diese Form ist sehr aufwendig, da die Anzahl möglicher Pfade schnell stark ansteigt. - Function Coverage
Misst, welche Funktionen überhaupt durch Tests aufgerufen wurden.
In vielen Projekten wird Code Coverage als Prozentwert angegeben: „85 % Statement Coverage“ oder „100 % Branch Coverage“. Dieser Wert wirkt auf den ersten Blick eindeutig, ist aber allein noch kein Qualitätsbeweis. Hohe Coverage bedeutet nicht automatisch gute Tests. Sie zeigt nur, dass viel Code ausgeführt wurde. Ob dieser Code mit sinnvollen Eingaben, realistischen Fehlerfällen und plausiblen Grenzwerten getestet wurde, ist eine andere Frage.
Gerade deshalb wird Code Coverage oft missverstanden. Sie ist kein Beweis für Fehlerfreiheit. Code Coverage ist ein Analysewerkzeug, um blinde Flecken im Testsystem, zum Beispiel in Form von Dead Code sichtbar zu machen. Wenn bestimmte Codeteile nie ausgeführt werden, dann existiert dort faktisch keine Testaussage. Ohne Coverage-Messung bleibt das in vielen Projekten unbemerkt.
Code Coverage für Embedded Systems
Für Embedded-Systeme ist Code Coverage besonders wichtig, weil dort mehrere Randbedingungen zusammenkommen, die Tests erschweren:
Erstens ist Embedded-Software häufig eng an reale Hardware gekoppelt. Ein Teil des Codes reagiert auf Interrupts, Timer, DMA, Peripherieregister, Kommunikationsframes oder Fehlerzustände externer Bauteile. Solche Situationen treten im normalen Funktionstest oft nicht vollständig oder nur zufällig auf. Ohne Coverage-Auswertung bleibt unklar, ob diese Abschnitte jemals getestet wurden.
Zweitens enthalten Embedded-Systeme oft viele Ausnahme- und Fallback-Pfade. Dazu gehören Watchdog-Reaktionen, Fehlerbehandlung bei Kommunikationsabbrüchen, Spannungsprobleme, Speicherfehler, Timeouts, ungültige Sensordaten oder Startprobleme im Bootprozess. Diese Pfade sind im Alltag gerade deshalb selten sichtbar, weil sie nur unter Störbedingungen aktiviert werden. Aus Sicherheits- und Zuverlässigkeitssicht sind sie aber oft wichtiger als der nominale Hauptpfad. Code Coverage hilft hier zu prüfen, ob solche Fehlerbehandlungsmechanismen überhaupt einmal bewusst ausgelöst und getestet wurden.
Drittens sind Embedded-Produkte häufig langlebig und werden in industriellen, mobilen, sicherheitsbezogenen oder rauen Umgebungen betrieben. Fehler zeigen sich dann nicht nur als Absturz einer Anwendung, sondern möglicherweise als Stillstand eines Geräts, fehlerhafte Messwerte, Kommunikationsausfall oder gefährlicher Systemzustand. In solchen Umgebungen reicht ein oberflächlicher Funktionstest nicht aus. Die Frage, welche Teile des Codes tatsächlich verifiziert wurden, wird damit zu einer technischen und oft auch regulatorischen Notwendigkeit.
Viertens ist die Beobachtbarkeit bei Embedded-Systemen oft schlechter als bei PC- oder Cloud-Software. Es gibt meist kein vollständiges Logging, keine komfortable Runtime-Inspektion und keine einfache Reproduzierbarkeit aller Zustände. Coverage-Messung schafft hier eine zusätzliche Ebene von Transparenz. Sie zeigt, was während eines Tests auf dem Target oder in der Testumgebung wirklich passiert ist.
Sicherheitskritische Elektronik
Ein weiterer wichtiger Punkt ist die Rolle von Code Coverage in regulierten oder sicherheitskritischen Entwicklungsprozessen. In Bereichen wie Automotive, Railway, Aerospace, Industrial Safety oder Medizintechnik wird Testabdeckung oft nicht nur technisch, sondern auch prozessual bewertet. Dort dient Coverage als Nachweis, dass Anforderungen und Implementierung systematisch überprüft wurden. Besonders relevant wird das in Verbindung mit Standards und Methoden wie struktureller Coverage, MC/DC oder anforderungsspezifischer Testfallableitung.
Im Embedded-Kontext wird häufig zwischen Tests auf verschiedenen Ebenen unterschieden:
- Unit Tests auf Host oder Target
- Integrationstests mit realen Schnittstellen
- Hardware-nahe Tests
- Systemtests
- Fehlereinbringung oder Robustheitstests
Code Coverage kann auf all diesen Ebenen unterschiedlich wertvoll sein. Ein Unit Test erreicht oft gute Coverage in isolierten Modulen, während hardwareabhängige Zustände dort gar nicht abgebildet werden. Ein Systemtest deckt reale Abläufe besser ab, erreicht aber oft weniger gezielt bestimmte seltene Zweige. Deshalb ist Coverage besonders nützlich, wenn sie nicht isoliert betrachtet wird, sondern als Kombination aus mehreren Testebenen.
Mehr zur Code Coverage im sicherheitskritischen Kontext in diesem Beitrag von Martin Heininger.
Bedeutung von Code Coverage
Warum ist Code Coverage nun konkret wichtig in Embedded-Projekten?
Sichtbarkeit für ungetesteten Code
In gewachsenen Embedded-Codebasen gibt es oft alte Funktionen, Legacy-Routinen, Sonderfälle oder defensive Programmteile, die niemand mehr aktiv betrachtet. Coverage macht sichtbar, welche Teile zwar im Build enthalten sind, aber nie getestet werden. Das ist insbesondere bei portierter Software, Plattformwechseln oder langen Produktzyklen relevant.
Nachweis für Fehlerbehandlung und Robustheit
Die interessantesten Bugs sitzen oft nicht im nominalen Hauptpfad, sondern in Sonderfällen. Coverage zeigt, ob Recovery-Strategien, Fehlerflags, Retry-Mechanismen, Timeout-Handling oder Safe-State-Übergänge überhaupt getestet wurden.
Bessere Testpriorisierung
Wenn Coverage-Daten vorliegen, lassen sich Testlücken gezielt schließen. Statt weitere beliebige Tests zu schreiben, kann das Team gezielt auf nicht erreichte Verzweigungen, Bedingungen oder Funktionen schauen.
Unterstützung bei Refactoring und Portierung
Gerade bei Embedded-Portierungen auf neue Mikrocontroller, RTOS-Versionen, Compiler oder Hardwareplattformen ist Coverage wertvoll. Sie hilft zu beurteilen, ob die bestehende Testbasis den relevanten Code nach der Umstellung weiterhin erreicht oder ob wichtige Pfade verloren gegangen sind.
Unterstützung für Safety und Security
Auch wenn Coverage allein weder Safety noch Security garantiert, ist sie ein wichtiges Fundament. Sicherheitsrelevante Plausibilitätsprüfungen, Rechteprüfungen, Secure-Boot-Entscheidungen, Fehlerreaktionen oder Kommunikationsvalidierungen sollten nicht nur vorhanden sein, sondern im Test nachweislich ausgeführt werden.
Reduktion von Scheinsicherheit
Viele Projekte haben umfangreiche Testsuiten und trotzdem große Lücken. Ohne Coverage entsteht leicht der Eindruck, „viel getestet“ zu haben. Coverage zwingt zu einer nüchternen Betrachtung: Was wurde tatsächlich ausgeführt und was nicht?
Bewertung und Metriken
Besonders wichtig ist die Unterscheidung zwischen guter und schlechter Nutzung von Coverage. Schlechte Nutzung bedeutet, nur auf eine Zielzahl zu optimieren, etwa „wir brauchen 90 %“. Das führt oft dazu, triviale Tests zu schreiben, die nur Zeilen berühren, aber kaum Aussagekraft haben. Gute Nutzung bedeutet, Coverage als Diagnoseinstrument zu verwenden: Welche sicherheitsrelevanten, fehlerkritischen oder hardwareabhängigen Teile sind noch ungetestet? Wo fehlen gezielte Negativtests? Welche Branches wurden nie erreicht?
In Embedded-Systemen treten außerdem technische Herausforderungen bei der Coverage-Messung selbst auf. Anders als bei Desktop-Software läuft der Code oft auf Mikrocontrollern mit begrenztem Speicher, eingeschränkter Laufzeitbeobachtung oder harter Echtzeitanforderung. Instrumentierung für Coverage kann Timing verändern, Speicher verbrauchen oder bestimmte Effekte verfälschen. Deshalb muss immer bewertet werden, wo und wie Coverage gemessen wird:
- auf dem Host in einer simulierten Umgebung,
- auf dem realen Target,
- mit Compiler-Instrumentierung,
- über Trace-Hardware,
- oder in Kombination verschiedener Methoden.
Jede Methode hat Grenzen. Host-basierte Tests sind schneller und leichter automatisierbar, bilden aber Registerzugriffe, Interrupt-Timing oder Hardwarefehler oft nur unvollständig ab. Target-basierte Messungen sind realitätsnäher, aber aufwendiger und teurer. Für viele Embedded-Projekte ist deshalb ein hybrider Ansatz sinnvoll.
Ein weiterer Aspekt: Nicht jeder Code sollte gleich bewertet werden. In Embedded-Projekten gibt es oft Abschnitte, die schwer oder nur indirekt testbar sind, etwa Start-up-Code, Compiler-Generated Code, Hardware-Abstraction-Layer, Exception-Handler, Bootloader-Teile oder Diagnosepfade unter seltenen Hardwarefehlern. Diese Teile dürfen nicht einfach ignoriert werden, aber sie erfordern oft eine separate Begründung. Gute Entwicklungsprozesse dokumentieren deshalb auch, warum bestimmte Bereiche nicht oder nur eingeschränkt durch Coverage erfasst wurden.
Im sicherheitsbezogenen Umfeld wird häufig auch von struktureller Coverage gesprochen. Gemeint ist dann die systematische Analyse, welche Strukturen des Programms durch Tests aktiviert wurden. Je nach Standard können unterschiedliche Anforderungen gelten. Besonders bekannt ist in diesem Zusammenhang MC/DC (Modified Condition/Decision Coverage), bei der nachgewiesen werden soll, dass einzelne Bedingungen innerhalb einer Entscheidung den Ausgang unabhängig beeinflussen können. Das ist vor allem bei sicherheitskritischer Logik relevant, etwa in Schutzfunktionen, Zustandsautomaten oder Freigabemechanismen.
Zusammenfassung
Code Coverage ist kein Selbstzweck und keine Kennzahl für Management-Folien allein. In der Embedded-Entwicklung ist sie vor allem deshalb wertvoll, weil sie die Lücke zwischen vorhandenen Tests und tatsächlich ausgeführtem Code sichtbar macht. Sie zeigt nicht, ob ein Produkt gut ist, aber sie zeigt sehr klar, wo noch keine belastbare Testaussage existiert.
Code Coverage ist ein Werkzeug zur Bewertung der Testabdeckung auf Code-Ebene. Sie hilft, ungetestete Anweisungen, Verzweigungen, Bedingungen und Fehlerpfade sichtbar zu machen. In Embedded-Systemen ist sie besonders wichtig, weil dort hardwareabhängige Zustände, Ausnahmefälle, Recovery-Mechanismen und sicherheitsrelevante Funktionen oft nicht automatisch durch Standardtests erreicht werden.
Für die Elektronik- und Embedded-Entwicklung bedeutet das konkret: Wer nur den Normalbetrieb testet, testet oft gerade nicht die Stellen, an denen Systeme im Feld scheitern. Code Coverage macht diese Lücken sichtbar und ist deshalb ein zentrales Werkzeug für robuste Software, nachvollziehbare Verifikation und belastbare Entwicklungsprozesse.