
The requirements for embedded devices have increased significantly in recent years. Especially in areas such as machine learning (ML) and signal processing, there is a growing need for powerful yet energy-efficient solutions. Due to limited resources and processing power, Microcontroller often only second choice. The more costly and energy-intensive high-end processors such as Cortex-A or specialized GPU-based approaches are in the foreground. However, manufacturers are now pushing ahead with the new Cortex-M85 architecture.
The ARM Cortex M85 now offers a new standard for microcontrollers, specifically developed for the requirements of resource-efficient mobile systems. The M85 combines high deterministic processing power with innovative features that expand the use of MCUs beyond classic application fields. Furthermore, ULP (Ultra Low Power) applications are possible. The basis for the high data throughput required in the ML context is Helium technology, which, through the M-Profile Vector Extension (MVE), offers the possibility of more complex matrix operations.
M-Profile Vector Extension (MVE)
A core component of the Cortex M85 is MVE, which massively increases processing speed for ML models and signal processing. ML applications at the edge often rely on optimized matrix operations that were previously trained on powerful servers and then implemented on microcontrollers. By utilizing libraries like CMSIS-NN, these models can be efficiently executed on the Cortex M.
The Helium extension allows the Floating Point Unit (FPU) to be used as a 128-bit vector register, enabling 16 operations with 8-bit, 8 operations with 16-bit, or 4 operations with 32-bit to be performed in parallel. This results in up to four times the performance compared to a typical Cortex-M7 with similar performance parameters (clock, RAM/ROM). Practically, microcontroller abstraction is provided via the CMSIS library. ARM thus provides the necessary MVE instructions directly with the CMSIS-NN library, which significantly simplifies the applicability of ML applications.
The Helium technology of the Cortex M85 optimizes data processing through the concept of „beatwise“ execution, which is based on 8 vector registers, each with a length of 128 bits. These registers are divided into four equal sections of 32 bits each, referred to as „beats“ (A through D). Each beat represents 32 bits of computation, regardless of element size – for example, 1 x 32-bit MAC or 4 x 8-bit MAC.
A typical scenario, as illustrated in the following diagram, shows an alternating sequence of Vector Load (VLDR) and Vector MAC (VMLA) instructions over four clock cycles. In a classic 128-bit data path architecture, large portions of the hardware, such as the memory path and the MAC blocks, would often be underutilized. However, the MVE architecture breaks down each 128-bit-wide instruction into four equally sized beats. By separating the load and MAC hardware, the processing of these beats can be overlapped: while beat A of a VLDR is being loaded, beat A of a VMLA, which accesses data from the previous cycle, is simultaneously processed.
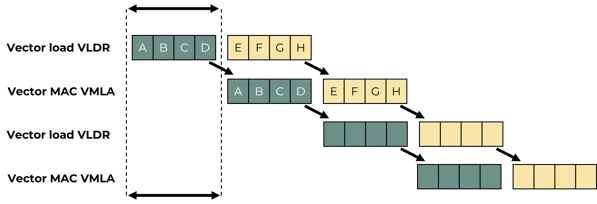
This overlapping design allows it to achieve the same performance as a processor with a 128-bit data path. Even with processors that only have a 32-bit data path, comparable instructions can be efficiently processed through „beatwise“ execution. Such a design doubles the performance of a single-issue scalar processor that can load 8 x 32-bit values and perform MAC calculations in eight cycles – and this without the high hardware overhead of a dual-issue design.
Low Overhead Branch Extension
Not only in the context of ML, but also with loop structures, processing efficiency has a significant impact on overall performance. The Cortex M85 introduces optimized pipeline control here with the new machine instructions WLS, DLS, and LE. These instructions minimize overhead in loop operations, as the beginning and end of the loop are stored directly in the core registers.
A special feature: The work of using these new instructions is handled by the compiler, so developers automatically benefit from improved performance. Even if the MVE extension is not implemented, the new loop instructions are available.
Half Precision Floating Point
To further increase computational performance, the FPU of the Cortex-M85 supports 16-bit half-precision operations in addition to 32-bit single-precision and 64-bit double-precision operations. This is particularly helpful when normalizing ML models, as calculations with smaller data types not only reduce memory usage but also increase computation speed – without risking significant quality loss.
Summary
The ARM Cortex M85 with Helium technology and MVE represents a significant advancement in the world of microcontrollers. It enables powerful applications in AI and signal processing that were previously reserved for more expensive processors. With its high deterministic computing power and innovative optimizations, the Cortex M85 demonstrates how to push the boundaries of classic MCU use cases.
